Hyperparameter Tuning with the Zalando Dataset¶
Version 1.0
(C) 2020 - Umberto Michelucci, Michela Sperti
This notebook is part of the book Applied Deep Learning: a case based approach, 2nd edition from APRESS by U. Michelucci and M. Sperti.
The purpose of this notebook is to give a practical example (with a dataset taken from the real world) of hyperparameter tuning with Feed-Forward Neural Networks.
Notebook Learning Goals¶
At the end of the notebook you are going to know how to tune the hyperparameters of a Feed-Forward Neural Network in Keras, with grid search and random search.
Dataset Overview¶
Context
Fashion-MNIST is a dataset of Zalando’s article images (consisting of a training set of 60000 examples and a test set of 10000 examples). Each example is a 28x28 grayscale image, associated with a label from 10 classes. Zalando intends Fashion-MNIST to serve as a direct drop-in replacement for the original MNIST dataset for benchmarking machine learning algorithms. It shares the same image size and structure of training and testing splits.
The original MNIST dataset contains a lot of handwritten digits. Members of the AI/ML/Data Science community love this dataset and use it as a benchmark to validate their algorithms. In fact, MNIST is often the first dataset researchers try. “If it doesn’t work on MNIST, it won’t work at all”, they said. “Well, if it does work on MNIST, it may still fail on others.” Zalando seeks to replace the original MNIST dataset
Content
Each image is 28 pixels in height and 28 pixels in width, for a total of 784 pixels in total. Each pixel has a single pixel-value associated with it, indicating the lightness or darkness of that pixel, with higher numbers meaning darker. This pixel-value is an integer between 0 and 255. The training and test data sets have 785 columns. The first column consists of the class labels (see above), and represents the article of clothing. The rest of the columns contain the pixel-values of the associated image.
To locate a pixel on the image, suppose that we have decomposed \(x\) as \(x = 28i + j\), where \(i\) and \(j\) are integers between 0 and 27. The pixel is located on row \(i\) and column \(j\) of a 28x28 matrix. For example, pixel31 indicates the pixel that is in the fourth column from the left, and the second row from the top.
Each row of the dataset is a separate image. Column 1 is the class label. Remaining columns are pixel numbers (784 total). Each value is the darkness of the pixel (1 to 255).
Labels
Each training and test example is assigned to one of the following labels:
0 T-shirt/top
1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt
7 Sneaker
8 Bag
9 Ankle boot
Acknowledgements
Original dataset was downloaded from TensorFlow datasets catalog.
License
The MIT License (MIT) Copyright © [2017] Zalando SE, https://tech.zalando.com
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Libraries and Dataset Import¶
This section contains the necessary libraries (such as tensorflow or pandas) you need to import to run the notebook.
# This command install code from the tensorflow docs repository.
# We need to use tensorflow_docs.modeling function when training our model.
# This function will generate a report on the network's perfomances
# step by step during the training phase (see Training Phase section of the
# notebook).
# You can safely ignore this cell if you don't understand what it does.
!pip install git+https://github.com/tensorflow/docs
Collecting git+https://github.com/tensorflow/docs
Cloning https://github.com/tensorflow/docs to /tmp/pip-req-build-tmebecoo
Running command git clone -q https://github.com/tensorflow/docs /tmp/pip-req-build-tmebecoo
Requirement already satisfied: astor in /usr/local/lib/python3.7/dist-packages (from tensorflow-docs==0.0.0.dev0) (0.8.1)
Requirement already satisfied: absl-py in /usr/local/lib/python3.7/dist-packages (from tensorflow-docs==0.0.0.dev0) (0.12.0)
Requirement already satisfied: protobuf>=3.14 in /usr/local/lib/python3.7/dist-packages (from tensorflow-docs==0.0.0.dev0) (3.17.3)
Requirement already satisfied: pyyaml in /usr/local/lib/python3.7/dist-packages (from tensorflow-docs==0.0.0.dev0) (3.13)
Requirement already satisfied: six>=1.9 in /usr/local/lib/python3.7/dist-packages (from protobuf>=3.14->tensorflow-docs==0.0.0.dev0) (1.15.0)
# general libraries
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from random import *
import time
# tensorflow libraries
from tensorflow.keras.datasets import fashion_mnist
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_docs as tfdocs
import tensorflow_docs.modeling
# Referring to the following cell, if you want to re-clone a repository
# inside the google colab instance, you need to delete it first.
# You can delete the repositories contained in this instance executing
# the following two lines of code (deleting the # comment symbol).
# !rm -rf ADL-Book-2nd-Ed
# This command actually clone the repository of the book in the google colab
# instance. In this way this notebook will have access to the modules
# we have written for this book.
# Please note that in case you have already run this cell, and you run it again
# you may get the error message:
#
# fatal: destination path 'ADL-Book-2nd-Ed' already exists and is not an empty directory.
#
# In this case you can safely ignore the error message.
!git clone https://github.com/toelt-llc/ADL-Book-2nd-Ed.git
fatal: destination path 'ADL-Book-2nd-Ed' already exists and is not an empty directory.
# This cell imports some custom written functions that we have created to
# make the plotting easier. You don't need to undertsand the details and
# you can simply ignore this cell.
# Simply run it with CMD+Enter (on Mac) or CTRL+Enter (Windows or Ubuntu) to
# import the necessary functions.
import sys
sys.path.append('ADL-Book-2nd-Ed/modules/')
from style_setting import set_style
The following cells are needed to download the dataset.
((trainX, trainY), (testX, testY)) = fashion_mnist.load_data()
Helper Functions¶
def get_label_name(idx):
"""Returns the corresponding label's name, given its numerical value."""
if (idx == 0):
return '(0) T-shirt/top'
elif (idx == 1):
return '(1) Trouser'
elif (idx == 2):
return '(2) Pullover'
elif (idx == 3):
return '(3) Dress'
elif (idx == 4):
return '(4) Coat'
elif (idx == 5):
return '(5) Sandal'
elif (idx == 6):
return '(6) Shirt'
elif (idx == 7):
return '(7) Sneaker'
elif (idx == 8):
return '(8) Bag'
elif (idx == 9):
return '(9) Ankle boot'
def get_random_element_with_label (data, lbls, lbl):
"""Returns one numpy array (one column) with an example of a choosen label."""
tmp = lbls == lbl
subset = data[tmp.flatten(), :]
return subset[randint(1, subset.shape[1]), :]
Now you have all the necessary elements to successfully implement this tutorial. Let’s have a look at our data:
print('Dimensions of the training dataset: ', trainX.shape)
print('Dimensions of the test dataset: ', testX.shape)
print('Dimensions of the training labels: ', trainY.shape)
print('Dimensions of the test labels: ', testY.shape)
Dimensions of the training dataset: (60000, 28, 28)
Dimensions of the test dataset: (10000, 28, 28)
Dimensions of the training labels: (60000,)
Dimensions of the test labels: (10000,)
Dataset Preparation¶
We now one-hot encode the labels and change the images dimensions, to get easy to use data for later. To know more about one-hot encoding process see the Further Readings section or refer to the hands-on chapter of the book about feed-forward neural networks.
labels_train = np.zeros((60000, 10))
labels_train[np.arange(60000), trainY] = 1
data_train = trainX.reshape(60000, 784)
labels_test = np.zeros((10000, 10))
labels_test[np.arange(10000), testY] = 1
data_test = testX.reshape(10000, 784)
print('Dimensions of the training dataset: ', data_train.shape)
print('Dimensions of the test dataset: ', data_test.shape)
print('Dimensions of the training labels: ', labels_train.shape)
print('Dimensions of the test labels: ', labels_test.shape)
Dimensions of the training dataset: (60000, 784)
Dimensions of the test dataset: (10000, 784)
Dimensions of the training labels: (60000, 10)
Dimensions of the test labels: (10000, 10)
Data Normalization¶
Let’s normalize the training data dividing by 255.0 to get the values between 0 and 1.
data_train_norm = np.array(data_train/255.0)
data_test_norm = np.array(data_test/255.0)
Let’s plot an image as example.
idx = 5
plt.imshow(data_train_norm[idx, :].reshape(28, 28), cmap = matplotlib.cm.binary, interpolation = 'nearest')
plt.axis("on")
plt.title(get_label_name(trainY[idx]))
plt.show()

Now let’s plot one example of each type (label).
# The following code create a numpy array where in column 0 you will find
# an example of label 0, in column 1 of label 1 and so on.
labels_overview = np.empty([784, 10])
for i in range (0, 10):
col = get_random_element_with_label(data_train_norm, trainY, i)
labels_overview[:,i] = col
f = plt.figure(figsize = (15, 15))
count = 1
for i in range(0, 10):
plt.subplot(5, 2, count)
count = count + 1
plt.subplots_adjust(hspace = 0.5)
plt.title(get_label_name(i))
some_digit_image = labels_overview[:, i].reshape(28, 28)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation = "nearest")
plt.axis("off")
pass

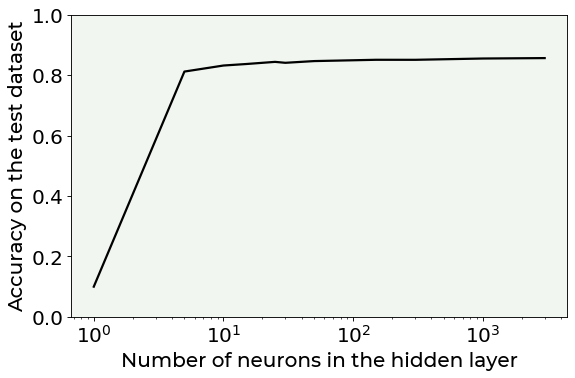
Exercises¶
[Easy Difficulty] Try different optimizers (for example Adam) and consider wider ranges for the parameters, more parameters combinations and so on. See how results change.
[Hard Difficulty] Try to implement Bayesian Optimization. You can find all implementation details in Chapter 8 of the book.
[Medium Difficulty] Try to optimize a multiclass classification model like the one we saw together in this notebook, but with a different dataset, the MNIST database of handwritten digits (http://yann.lecun.com/exdb/mnist/). To download the dataset from TensorFlow use the following lines of code:
from tensorflow import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
Further Readings ¶
Fashion-MNIST dataset
Xiao, Han, Kashif Rasul, and Roland Vollgraf. “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.” arXiv preprint arXiv:1708.07747 (2017)